Your new post is loading...
Many of the world’s languages are in danger of disappearing, and the limitations of current speech recognition and generation technology will only accelerate this trend. We want to make it easier for people to access information and use devices in their preferred language, and today we’re announcing a series of artificial intelligence (AI) models that could help them do just that. Massively Multilingual Speech (MMS) models expand text-to-speech and speech-to-text technology from around 100 languages to more than 1,100 — more than 10 times as many as before — and can also identify more than 4,000 spoken languages, 40 times more than before. There are also many use cases for speech technology — from virtual and augmented reality technology to messaging services — that can be used in a person’s preferred language and can understand everyone’s voice. We are open-sourcing our models and code so that others in the research community can build on our work and help preserve the world’s languages and bring the world closer together. Collecting audio data for thousands of languages was our first challenge because the largest existing speech datasets cover 100 languages at most. To overcome this, we turned to religious texts, such as the Bible, that have been translated in many different languages and whose translations have been widely studied for text-based language translation research. These translations have publicly available audio recordings of people reading these texts in different languages. As part of the MMS project, we created a dataset of readings of the New Testament in more than 1,100 languages, which provided on average 32 hours of data per language. By considering unlabeled recordings of various other Christian religious readings, we increased the number of languages available to more than 4,000. While this data is from a specific domain and is often read by male speakers, our analysis shows that our models perform equally well for male and female voices. And while the content of the audio recordings is religious, our analysis shows that this doesn’t bias the model to produce more religious language.
Almost as soon as we learn to talk, we learn to swear, says Emma Byrne, author of "Swearing is Good for You." Our closest cousins, chimpanzees, are fond of a bit of swearing. What’s more, swearing seems to spontaneously emerge just as soon as they - and we - have language and a taboo. There have been several attempts to teach chimpanzees sign language. The most successful by far are the heroic ones run by behaviorists Roger and Deborah Fouts. They were committed enough to foster several, living with them as if they were members of their own family, for many years. They started in 1966 with a ten month old fosterling, Washoe, who they immediately began to teach sign language and to potty train. Almost immediately, she started to use the sign DIRTY, intended for all things scatalogical, as an insult and an interjection. She spontaneously developed a potty mouth. It might seem like a stretch to talk about chimpanzees as having taboos, but Washoe and the rest of her chimpanzee family became incredibly fastidious about their toilet habits. Washoe was so thoroughly toilet trained that that she wouldn’t even defecate in the woods, holding it in until one of the humans in the group offered her an empty coffee can to use as a potty. We also know that toilet-trained chimpanzees lie if they’re caught accidentally (or deliberately) making a mess away from their toilet. DIRTY GOOD is the name that Washoe herself came up with for her potty. This name, which she invented herself, shows how nuanced her understanding of the excretion taboo was: pooing in a potty is necessary and acceptable, but crap out of context is shameful and wrong. Washoe and the other chimpanzees began to use DIRTY as an insult, when they were angry or frustrated. The humans never used it that way about the chimpanzees; the use of DIRTY as a curse by the chimpanzees was spontaneous. For example Washoe signed DIRTY ROGER when Fouts wouldn’t let her out of her cage and DIRTY MONKEY at a macaque who threatened her. It’s my hypothesis that the combination of learning a language and the excretion taboo is all it takes for swearing to emerge. That said, I can’t imagine anyone being brave enough to test my conjecture. In the wild, chimpanzees deliberately defecate on humans as a way of marking their territory, so trying to recreate the Fouts’ study without the potty training step would be a grim challenge. English speaking toddlers tend to show a similar pattern, however, commonly using “poo face” or “doodoo head” as soon as they’re potty trained - again, not something they’re likely to have heard from parents. I can’t wait for my daughter to reach that stage: research from the 1930s shows that among toddlers, the development of a pottymouth comes with at least one fringe benefit. Swearing replaces biting, hitting, screaming and breath-holding as ways of externalising strong feelings in human children, and in chimpanzees too. The chimpanzees only seem to have had the one sign that they used as swearing - probably because it was their only taboo. When Washoe hit adolescence she began masturbating, but the research team decided that discretion was the better part of valor and didn’t intervene, so there was no equivalent of the copulatory taboo that accounts for so much human swearing.
Here is the solution to her puzzle on the TED website "There are about 7,000 languages spoken around the world -- and they all have different sounds, vocabularies and structures. But do they shape the way we think? Cognitive scientist Lera Boroditsky shares examples of language -- from an Aboriginal community in Australia that uses cardinal directions instead of left and right to the multiple words for blue in Russian -- that suggest the answer is a resounding yes. 'The beauty of linguistic diversity is that it reveals to us just how ingenious and how flexible the human mind is,' Broditsky says. Human minds have invented not one cognitive universe, but 7,000." Follow Dr. Broditsky to Pormpuraaw, a small Aboriginal community on the western edge of Cape York in northern Australia. She went there because of the way the locals, the Kuuk Thaayorre, talk about space. Instead of words like "right," "left," "forward," and "back," which, as commonly used in English, define space relative to an observer, the Kuuk Thaayorre, like many other Aboriginal groups, use cardinal-direction terms — north, south, east, and west — to define space. This is done at all scales, which means you have to say things like "There's an ant on your southeast leg" or "Move the cup to the north northwest a little bit." One obvious consequence of speaking such a language is that you have to stay oriented at all times, or else you cannot speak properly. The normal greeting in Kuuk Thaayorre is "Where are you going?" and the answer should be something like " Southsoutheast, in the middle distance." If you don't know which way you're facing, you can't even get past "Hello." The result is a profound difference in navigational ability and spatial knowledge between speakers of languages that rely primarily on absolute reference frames (like Kuuk Thaayorre) and languages that rely on relative reference frames (like English). Simply put, speakers of languages like Kuuk Thaayorre are much better than English speakers at staying oriented and keeping track of where they are, even in unfamiliar landscapes or inside unfamiliar buildings. What enables them — in fact, forces them — to do this is their language. Having their attention trained in this way equips them to perform navigational feats once thought beyond human capabilities. Because space is such a fundamental domain of thought, differences in how people think about space don't end there. People rely on their spatial knowledge to build other, more complex, more abstract representations. Representations of such things as time, number, musical pitch, kinship relations, morality, and emotions have been shown to depend on how we think about space. So if the Kuuk Thaayorre think differently about space, do they also think differently about other things, like time? This is why Dr. Broditsky and her collaborator Alice Gaby came to Pormpuraaw to find out. To test this idea, we gave people sets of pictures that showed some kind of temporal progression (e.g., pictures of a man aging, or a crocodile growing, or a banana being eaten). Their job was to arrange the shuffled photos on the ground to show the correct temporal order. We tested each person in two separate sittings, each time facing in a different cardinal direction. If you ask English speakers to do this, they'll arrange the cards so that time proceeds from left to right. Hebrew speakers will tend to lay out the cards from right to left, showing that writing direction in a language plays a role. So what about folks like the Kuuk Thaayorre, who don't use words like "left" and "right"? What will they do? The Kuuk Thaayorre did not arrange the cards more often from left to right than from right to left, nor more toward or away from the body. But their arrangements were not random: there was a pattern, just a different one from that of English speakers. Instead of arranging time from left to right, they arranged it from east to west. That is, when they were seated facing south, the cards went left to right. When they faced north, the cards went from right to left. When they faced east, the cards came toward the body and so on. This was true even though we never told any of our subjects which direction they faced. The Kuuk Thaayorre not only knew that already (usually much better than Dr. Broditsky herself did), but they also spontaneously used this spatial orientation to construct their representations of time. Which is amazing. A transcript of the talk is here
Via Skuuppilehdet
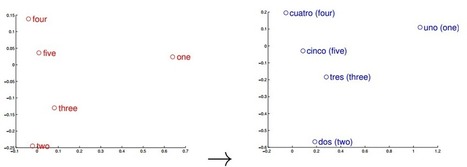
To translate one language into another, find the linear transformation that maps one to the other. Simple, say a team of Google engineers Computer science is changing the nature of the translation of words and sentences from one language to another. Anybody who has tried BabelFish or Google Translate will know that they provide useful translation services but ones that are far from perfect. The basic idea is to compare a corpus of words in one language with the same corpus of words translated into another. Words and phrases that share similar statistical properties are considered equivalent. The problem, of course, is that the initial translations rely on dictionaries that have to be compiled by human experts and this takes significant time and effort. Now Tomas Mikolov and a couple of pals at Google in Mountain View have developed a technique that automatically generates dictionaries and phrase tables that convert one language into another. The new technique does not rely on versions of the same document in different languages. Instead, it uses data mining techniques to model the structure of a single language and then compares this to the structure of another language. “This method makes little assumption about the languages, so it can be used to extend and refine dictionaries and translation tables for any language pairs,” they say. The new approach is relatively straightforward. It relies on the notion that every language must describe a similar set of ideas, so the words that do this must also be similar. For example, most languages will have words for common animals such as cat, dog, cow and so on. And these words are probably used in the same way in sentences such as “a cat is an animal that is smaller than a dog.” The same is true of numbers. The image above shows the vector representations of the numbers one to five in English and Spanish and demonstrates how similar they are. This is an important clue. The new trick is to represent an entire language using the relationship between its words. The set of all the relationships, the so-called “language space”, can be thought of as a set of vectors that each point from one word to another. And in recent years, linguists have discovered that it is possible to handle these vectors mathematically. For example, the operation ‘king’ – ‘man’ + ‘woman’ results in a vector that is similar to ‘queen’. It turns out that different languages share many similarities in this vector space. That means the process of converting one language into another is equivalent to finding the transformation that converts one vector space into the other. Having identified this mapping, it is then a simple matter to apply it to the bigger language spaces. Mikolov and co say it works remarkably well. “Despite its simplicity, our method is surprisingly effective: we can achieve almost 90% precision@5 for translation of words between English and Spanish,” they say. The method can be used to extend and refine existing dictionaries, and even to spot mistakes in them. Indeed, the Google team do exactly that with an English-Czech dictionary, finding numerous mistakes. Finally, the team point out that since the technique makes few assumptions about the languages themselves, it can be used on argots that are entirely unrelated. So while Spanish and English have a common Indo-European history, Mikolov and co show that the new technique also works just as well for pairs of languages that are less closely related, such as English and Vietnamese.
University of British Columbia and Berkeley researchers have used a sophisticated new computer system to quickly reconstruct protolanguages – the rudimentary ancient tongues from which modern languages evolved. University of British Columbia and Berkeley researchers have used a sophisticated new computer system to quickly reconstruct protolanguages – the rudimentary ancient tongues from which modern languages evolved The results, which are 85 per cent accurate when compared to the painstaking manual reconstructions performed by linguists, will be published next week in the Proceedings of the National Academy of Sciences. "We're hopeful our tool will revolutionize historical linguistics much the same way that statistical analysis and computer power revolutionized the study of evolutionary biology," says UBC Assistant Prof. of Statistics Alexandre Bouchard-Côté, lead author of the study. "And while our system won't replace the nuanced work of skilled linguists, it could prove valuable by enabling them to increase the number of modern languages they use as the basis for their reconstructions." Protolanguages are reconstructed by grouping words with common meanings from related modern languages, analyzing common features, and then applying sound-change rules and other criteria to derive the common parent. The new tool designed by Bouchard-Côté and colleagues at the University of California, Berkeley analyzes sound changes at the level of basic phonetic units, and can operate at much greater scale than previous computerized tools. The researchers reconstructed a set of protolanguages from a database of more than 142,000 word forms from 637 Austronesian languages—spoken in Southeast Asia, the Pacific and parts of continental Asia.
Gerhard Jäger uses lexostatistics to demonstrate that language similarities can be computed without using tree-based representations (for why this might be important, see Kevin’s post on reconstructing linguistic phylogenies).
Via Sakis Koukouvis
|
How a determined student made Sanskrit’s ‘language machine’ work for the first time in 2,500 years A grammatical problem which has defeated Sanskrit scholars since the 5th Century BC has finally been solved by an Indian PhD student at the University of Cambridge. Rishi Rajpopat made the breakthrough by decoding a rule taught by "the father of linguistics" Pāṇini. The discovery makes it possible to 'derive' any Sanskrit word -- to construct millions of grammatically correct words including 'mantra' and 'guru' -- using Pāṇini's revered 'language machine' which is widely considered to be one of the great intellectual achievements in history. Leading Sanskrit experts have described Rajpopat's discovery as 'revolutionary' and it could now mean that Pāṇini's grammar can be taught to computers for the first time. While researching his PhD, published today, Dr Rajpopat decoded a 2,500 year old algorithm which makes it possible, for the first time, to accurately use Pāṇini's 'language machine'. Pāṇini's system -- 4,000 rules detailed in his greatest work, the Aṣṭādhyāyī, which is thought to have been written around 500BC -- is meant to work like a machine. Feed in the base and suffix of a word and it should turn them into grammatically correct words and sentences through a step-by-step process. Until now, however, there has been a big problem. Often, two or more of Pāṇini's rules are simultaneously applicable at the same step leaving scholars to agonise over which one to choose. Solving so-called 'rule conflicts', which affect millions of Sanskrit words including certain forms of 'mantra' and 'guru', requires an algorithm. Pāṇini taught a metarule* to help us decide which rule should be applied in the event of 'rule conflict' but for the last 2,500 years, scholars have misinterpreted this metarule meaning that they often ended up with a grammatically incorrect result. In an attempt to fix this issue, many scholars laboriously developed hundreds of other metarules but Dr Rajpopat shows that these are not just incapable of solving the problem at hand -- they all produced too many exceptions -- but also completely unnecessary. Rajpopat shows that Pāṇini's 'language machine' is 'self-sufficient'. Rajpopat said: "Pāṇini had an extraordinary mind and he built a machine unrivalled in human history. He didn't expect us to add new ideas to his rules. The more we fiddle with Pāṇini's grammar, the more it eludes us." Traditionally, scholars have interpreted Pāṇini's metarule as meaning: in the event of a conflict between two rules of equal strength, the rule that comes later in the grammar's serial order wins. Rajpopat rejects this, arguing instead that Pāṇini meant that between rules applicable to the left and right sides of a word respectively, Pāṇini wanted us to choose the rule applicable to the right side. Employing this interpretation, Rajpopat found Pāṇini's language machine produced grammatically correct words with almost no exceptions. Take 'mantra' and 'guru' as examples. In the sentence 'devāḥ prasannāḥ mantraiḥ' ('The Gods [devāḥ] are pleased [prasannāḥ] by the mantras [mantraiḥ]') we encounter 'rule conflict' when deriving mantraiḥ 'by the mantras'. The derivation starts with 'mantra + bhis'. One rule is applicable to left part 'mantra' and the other to right part 'bhis'. We must pick the rule applicable to the right part 'bhis', which gives us the correct form 'mantraiḥ'. And in the the sentence 'jñānaṁ dīyate guruṇā' ('Knowledge [jñānaṁ] is given [dīyate] by the guru [guruṇā]') we encounter rule conflict when deriving guruṇā 'by the guru'. The derivation starts with 'guru + ā'. One rule is applicable to left part 'guru' and the other to right part 'ā'. We must pick the rule applicable to the right part 'ā', which gives us the correct form 'guruṇā'. Eureka moment Six months before Rajpopat made his discovery, his supervisor at Cambridge, Vincenzo Vergiani, Professor of Sanskrit, gave him some prescient advice: "If the solution is complicated, you are probably wrong." Rajpopat said: "I had a eureka moment in Cambridge. After 9 months trying to crack this problem, I was almost ready to quit, I was getting nowhere. So I closed the books for a month and just enjoyed the summer, swimming, cycling, cooking, praying and meditating. Then, begrudgingly I went back to work, and, within minutes, as I turned the pages, these patterns starting emerging, and it all started to make sense. There was a lot more work to do but I'd found the biggest part of the puzzle." "Over the next few weeks I was so excited, I couldn't sleep and would spend hours in the library including in the middle of the night to check what I'd found and solve related problems. That work took another two and half years."
The Voynich manuscript, sometimes described as the ‘world’s most mysterious text,’ may be written in proto-Romance, a language that arose from a blend of spoken Latin (Vulgar Latin) and other languages across the Mediterranean during the early Medieval period following the collapse of the Roman Empire and subsequently evolved into the many Romance languages. The manuscript originates from Castello Aragonese, an island castle and citadel off Ischia, Italy, and was compiled by a Dominican nun as a source of reference for Maria of Castile, Queen of Aragon, according to research by University of Bristol’s Dr. Gerard Cheshire. The Voynich manuscript, named after the Polish-American antiquarian book dealer Wilfrid M. Voynich, who acquired it in 1912, is a small book 23.5 x 16.2 cm of about 240 pages. Nearly every page of the manuscript contains scientific and botanical drawings in various shades of green, brown, yellow, blue, and red. The vellum used in the book was carbon dated to 1404-1438. Although the purpose and meaning of the manuscript had eluded scholars for decades, it took Dr. Cheshire two weeks to identify the language and writing system of the famously inscrutable document. “I experienced a series of ‘Eureka!’ moments whilst deciphering the code, followed by a sense of disbelief and excitement when I realized the magnitude of the achievement, both in terms of its linguistic importance and the revelations about the origin and content of the manuscript,” Dr. Cheshire said. “The Voynich manuscript is written in proto-Romance — ancestral to today’s Romance languages including Portuguese, Spanish, French, Italian, Romanian, Catalan and Galician. The language used was ubiquitous in the Mediterranean during the Medieval period, but it was seldom written in official or important documents because Latin was the language of royalty, church and government. As a result, proto-Romance was lost from the record, until now.” “The manuscript’s alphabet is a combination of unfamiliar and more familiar symbols. It includes no dedicated punctuation marks, although some letters have symbol variants to indicate punctuation or phonetic accents. All of the letters are in lower case and there are no double consonants. It includes diphthong, triphthongs, quadriphthongs and even quintiphthongs for the abbreviation of phonetic components. It also includes some words and abbreviations in Latin.”
Languages have an intriguing paradox. Languages with lots of speakers, such as English and Mandarin, have large vocabularies with relatively simple grammar. Yet the opposite is also true: Languages with fewer speakers have fewer words but complex grammars. Why does the size of a population of speakers have opposite effects on vocabulary and grammar? Through computer simulations, a Cornell cognitive scientist and his colleagues have shown that ease of learning may explain the paradox. Their work suggests that language, and other aspects of culture, may become simpler as our world becomes more interconnected. Their study was published Jan. 24 in the Proceedings of the Royal Society B: Biological Sciences.“We were able to show that whether something is easy to learn – like words – or hard to learn – like complex grammar – can explain these opposing tendencies,” said co-author Morten Christiansen, professor of psychology and co-director of the Cognitive Science Program. The researchers hypothesized that words are easier to learn than aspects of morphology or grammar. “You only need a few exposures to a word to learn it, so it’s easier for words to propagate,” he said. But learning a new grammatical innovation requires a lengthier learning process. And that’s going to happen more readily in a smaller speech community, because each person is likely to interact with a large proportion of the community, he said. “If you have to have multiple exposures to, say, a complex syntactic rule, in smaller communities it’s easier for it to spread and be maintained in the population.” Conversely, in a large community, like a big city, one person will talk only to a small proportion the population. This means that only a few people might be exposed to that complex grammar rule, making it harder for it to survive, he said.
Research by the University of Liverpool has found that the same brain activity is used for language production and making complex tools, supporting the theory that they evolved at the same time. Researchers from the University tested the brain activity of 10 expert stone tool makers (flint knappers) as they undertook a stone tool-making task and a standard language test.
They measured the brain blood flow activity of the participants as they performed both tasks using functional Transcranial Doppler Ultrasound (fTCD), commonly used in clinical settings to test patients’ language functions after brain damage or before surgery. The researchers found that brain patterns for both tasks correlated, suggesting that they both use the same area of the brain. Language and stone tool-making are considered to be unique features of humankind that evolved over millions of years. Darwin was the first to suggest that tool-use and language may have co-evolved, because they both depend on complex planning and the coordination of actions but until now there has been little evidence to support this. Dr Georg Meyer, from the University Department of Experimental Psychology, said: “This is the first study of the brain to compare complex stone tool-making directly with language. “Our study found correlated blood-flow patterns in the first 10 seconds of undertaking both tasks. This suggests that both tasks depend on common brain areas and is consistent with theories that tool-use and language co-evolved and share common processing networks in the brain.” Dr Natalie Uomini from the University’s Department of Archaeology, Classics & Egyptology, said: “Nobody has been able to measure brain activity in real time while making a stone tool. This is a first for both archaeology and psychology.”
It's an almost universal truth that any language you don't understand sounds like it's being spoken at 200 m.p.h. — a storm of alien syllables almost impossible to tease apart. That, we tell ourselves, is simply because the words make no sense to us. Surely our spoken English sounds just as fast to a native speaker of Urdu. And yet it's equally true that some languages seem to zip by faster than others. Spanish blows the doors off French; Japanese leaves German in the dust — or at least that's how they sound. A new research study has found answers to why that is.
The idea that your mother tongue shapes your experience of the world may be true after all. Seventy years ago, in 1940, a popular science magazine published a short article that set in motion one of the trendiest intellectual fads of the 20th century.
|